Common pitfals
Working with blueprints can be both invigorating and challenging simultaneously. In this section, we will highlight some of the most common pitfalls to be aware of when designing systems using RUAL.
Not utilizing cache properly
From our experience in designing high-scale, high-performance systems, it is crucial to differentiate when data needs to be real-time and when it can be effectively utilized from a cache. In many instances, it suffices to retrieve data that would typically be requested directly from a storage system from a cached source.
A common misconception is that the search process is so rapid that caching is unnecessary. However, the reason for its speed is precisely because we encourage caching. Failure to utilize caching may result in the storage system providing less accurate information unless explicitly specified for high precision.
The utilization of a cache serves not only to enhance system performance but also to maintain that performance in high-scale operations. A single search query may not be a significant burden, but consider the scenario where the same query is executed 300 times within a minute due to 300 simultaneous page visits. In such cases, it would have been far more cost-effective to check if cached data is available, use it, and only request data from the storage when absolutely necessary.

Real-time search results
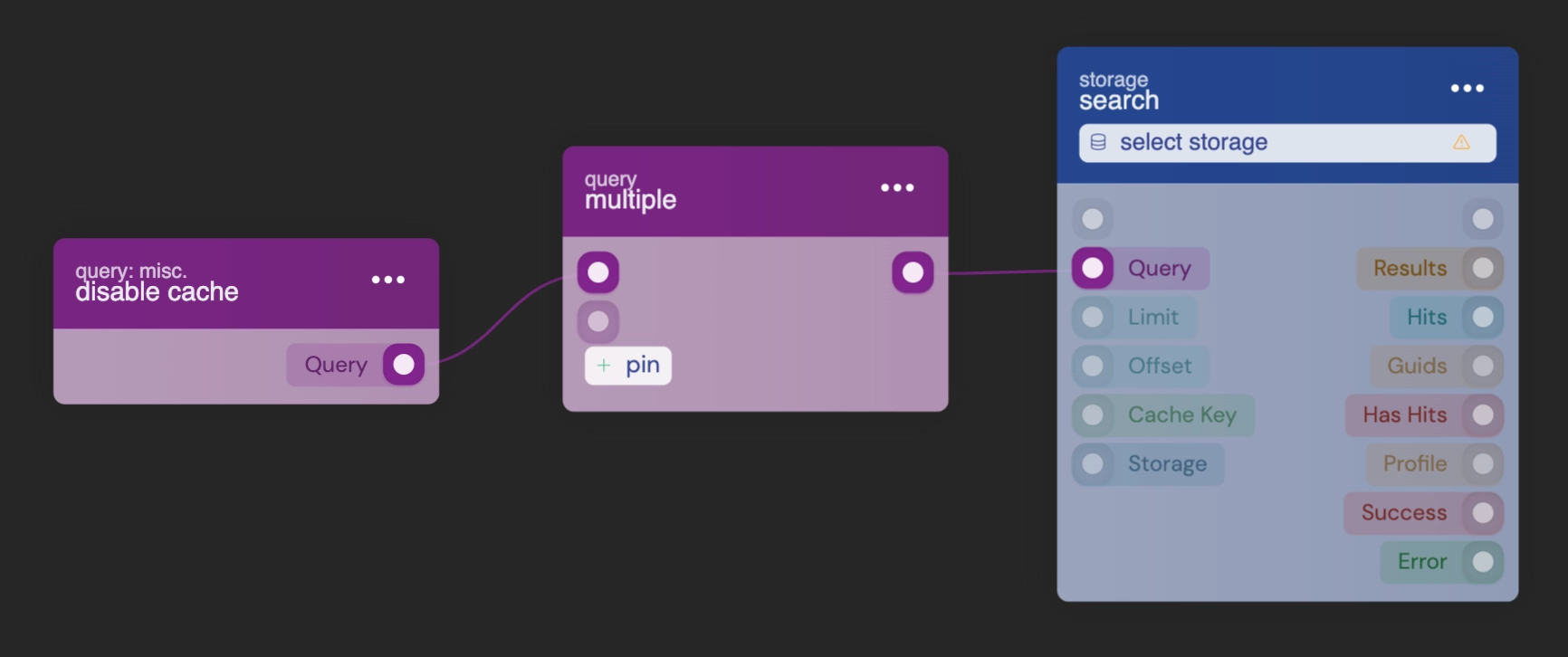
When performing a search query directed to a storage, the system does not wait for inserts to complete. Instead, it provides you with the most accurate data it currently has available. In some cases, this may result in a slight delay in the search data being updated. You might expect the newly created document to be included in the results, but it hasn't been incorporated into the search engine's data yet.
If it is crucial for your system's functionality to have the latest and most up-to-date data, you can incorporate the disable cache option in your query. This instructs the core to wait until the latest data has been inserted before executing the search query. However, in storage systems with a high rate of inserts, enabling this option could potentially lead to significant delays in the execution of the search query.
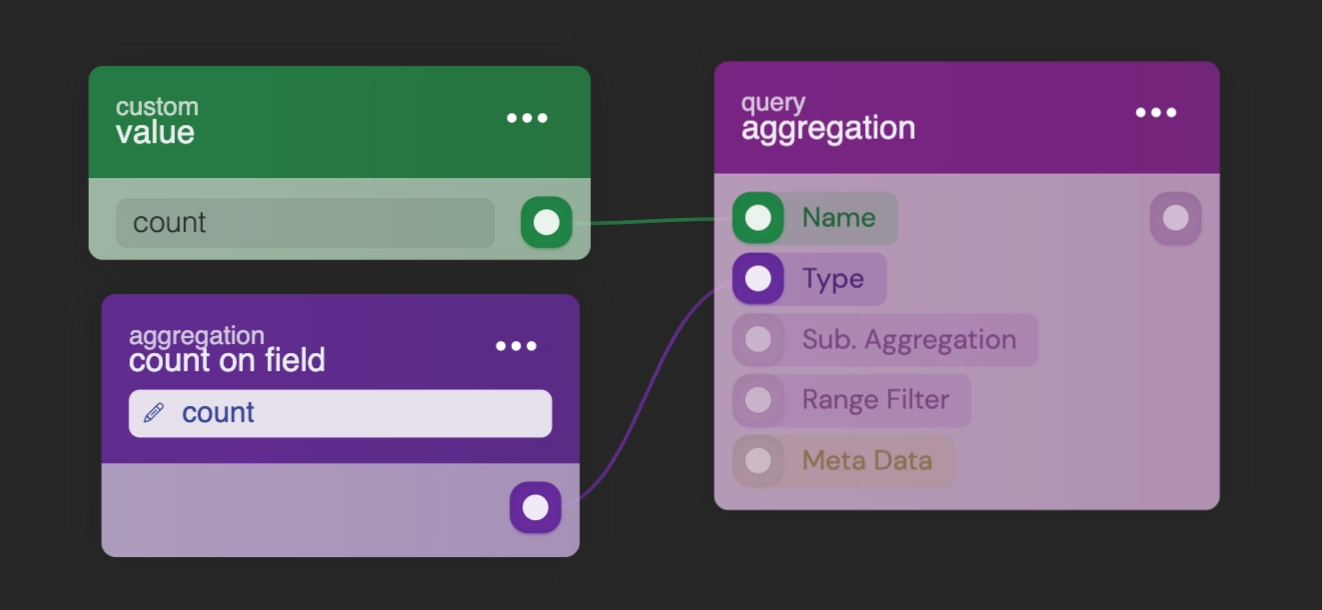
Inappropriate use of aggregations
Utilizing aggregation queries to consolidate data is indeed a powerful feature, but it comes at a significant cost. Aggregations should be reserved for sparingly updated storages; employing them on heavily populated storages can lead to performance degradation and excessive memory usage.
For efficient handling of aggregated data, it is advisable to store such information separately and retrieve it through standard queries. For example, when fetching aggregated data for users and you want to keep a count of their posts, it is more efficient to maintain a count attribute within the user object and increment it as necessary.
Alternatively, you can leverage Redis cache to store aggregated statistics. This approach involves storing JSON with aggregated results from relevant queries, making counts instantly accessible in milliseconds. These counts can be updated periodically using a time interval or in response to storage events.