Storage
RUAL includes a built-in, JSON-based storage system with full-text search. Learn how to create, update, search, and manage documents.
Storing Data
Blueprints include enterprise-scale storage, accessible through blocks like search and create document. The storage is JSON-based and schema-less. You don't need to predefine any data structure. The tradeoff is that there are no relationships between storage entities, so you should include all necessary data within each document (denormalization).
Meta Data
Every document includes a _meta key with the following fields:
| Key | Description |
|---|---|
guid |
The unique identifier of the document. This is a generated hash and is immutable. |
expiry |
A Unix timestamp for the expiration date. Defaults to -1 (no expiry). |
entity |
Identifies which entity within the cluster this document belongs to. |
removed |
A Unix timestamp indicating removal. 0 means the document is active. |
created |
Unix timestamp of when the document was created. |
updated |
Unix timestamp of the last update. |
ums |
Creation timestamp in milliseconds. |
cms |
Last update timestamp in milliseconds. |
update_hash |
A hash for the most recent modification, part of the transaction-based update system. |
{
"username": "Joe",
"_meta": {
"guid": "a23575f49d0af385314c1f02280163374297e018a692e5e4ab85eb307ebf6ebc",
"expiry": -1,
"entity": 1,
"removed": 0,
"created": 1706396400,
"updated": 1706396400,
"ums": 1706396400803,
"cms": 1706396400362,
"update_hash": "60e27209fa93063b5605e41605c2722ed428cae0"
}
}Creating Documents
To create a document, you need a storage reference and a set of mutations that define the fields:
- Add a
storageblock and select the storage you want to write to. - Add a
mutations_set_bp_field_multipleblock to define the fields and their values. - Add a
function_create_documentblock, connect the storage and mutations to its in-pins, and connect the flow pin from your flow.
The function_create_document block returns the created document including the generated _meta with its unique guid.
{
"username": "joe",
"email": "joe@example.com",
"role": "editor",
"_meta": {
"guid": "a23575f49d0af385314c1f02280163374297e018a692e5e4ab85eb307ebf6ebc",
"expiry": -1,
"entity": 1,
"removed": 0,
"created": 1706396400,
"updated": 1706396400,
"ums": 1706396400803,
"cms": 1706396400362,
"update_hash": "60e27209fa93063b5605e41605c2722ed428cae0"
}
}Field Name Rules
Field names are always stored in lowercase. If you use UserName, it will be stored as username. Fields cannot include dots (.). If they do, RUAL automatically converts them into a nested object structure.
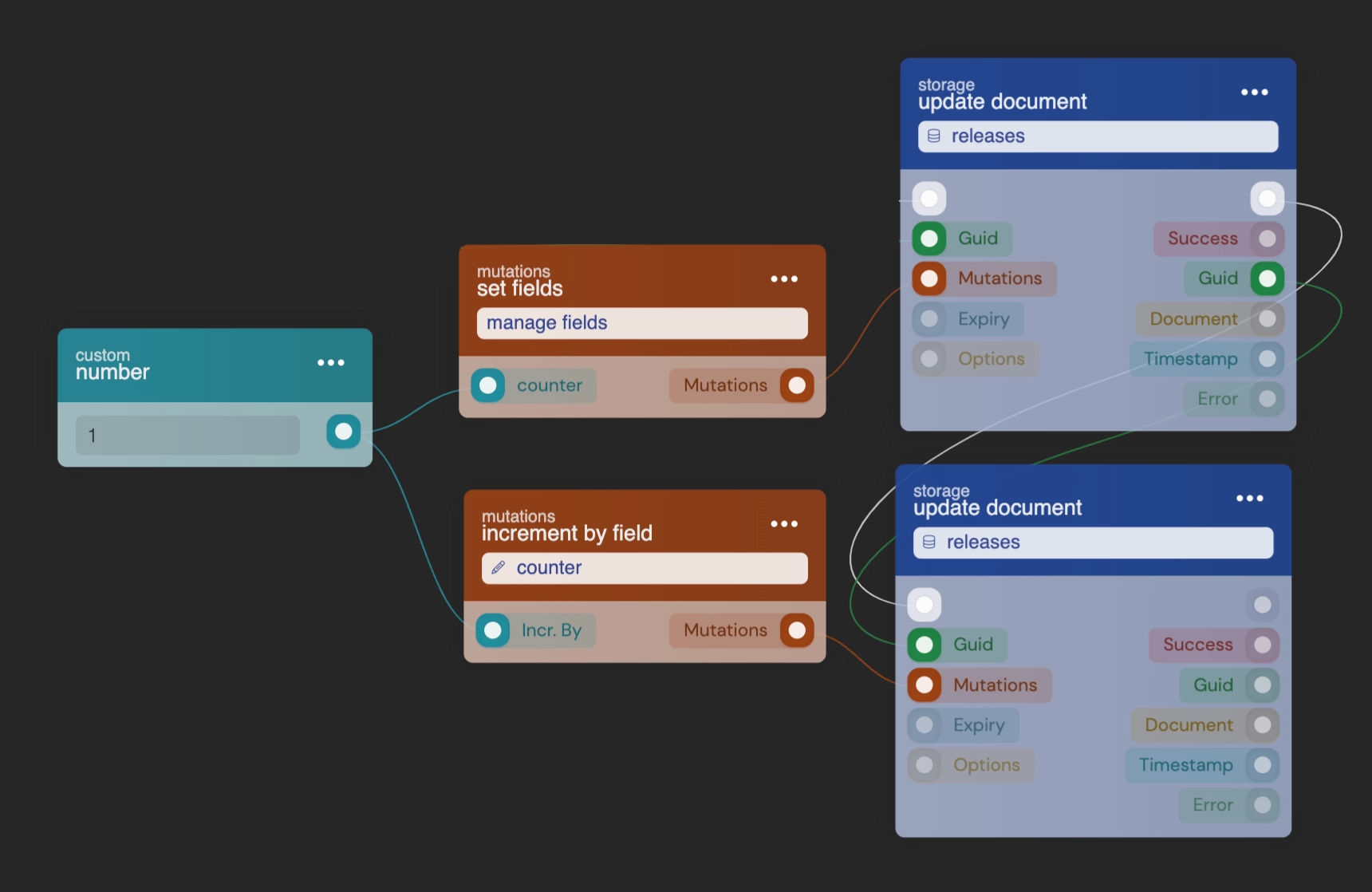
Updating Documents
Storage uses a transaction-based update system through mutations. Each update is processed sequentially, so concurrent updates won't overwrite each other. This makes counters and array operations safe to use.
To update a document, use the function_update_document block with the document's guid and the mutations you want to apply.
Common mutation operations:
| Block | Operation |
|---|---|
mutations_set_bp_field_multiple |
Set one or more fields to specific values. |
mutations_set_custom_field |
Set a field using a dynamic key and value. |
mutations_increment_by_field |
Increment a numeric field by a given amount. |
mutations_decrement_by_field |
Decrement a numeric field by a given amount. |
mutations_add_to_array_by_field |
Add a unique value to an array field. |
mutations_remove_from_array_by_field |
Remove a value from an array field. |
mutations_remove_by_field_multiple |
Remove one or more fields from the document entirely. |
mutations_add |
Combine multiple mutation sets into one. |
The execution result includes additional keys since it operates on an existing document:
{
"version": 130005,
"title": "v13.0.5",
"counter": 2,
"_meta": {
"guid": "723575f49d0af385314d1f02280163374297e018a692e5e4ab85eb907ebf6eb5",
"expiry": -1,
"entity": 1,
"removed": 0,
"created": 1706396400,
"updated": 1708393100,
"ums": 1706396400803,
"cms": 1708393100132,
"update_hash": "30e27209fa93073b5605e41605c2722ed448cae1"
}
}Getting a Document by GUID
The fastest way to retrieve a document is by its _meta.guid using the function_get_document block. This is faster than searching and easier to cache. Avoid creating custom unique identifiers like code. Use _meta.guid instead.
To retrieve multiple documents at once, use the function_get_documents block with an array of GUIDs.
Building Search Queries
Search queries are built by connecting query blocks together and feeding them into a function_search block. A typical search flow looks like this:
- Create the query conditions using blocks like
query_bool_term_fields(exact match on a field). - Wrap them in a boolean query using
query_bool_filter,query_bool_must, orquery_bool_should. - Optionally add sorting with
query_sort_fieldand a limit withquery_limitor anumberblock connected to the limit pin. - Combine all query parts using
query_and. - Connect the final query output to the query in-pin of
function_search. - Select the storage on the
function_searchblock.
Search Query Example
This example finds documents in a messages storage where user_guid matches a specific value, sorted by creation date descending, limited to 10 results:
| Block | Purpose | Connects To |
|---|---|---|
value_default |
The user GUID to search for | query_bool_term_fields (user_guid field) |
query_bool_term_fields |
Match documents where user_guid equals the value |
query_bool_filter |
query_bool_filter |
Wrap the term query in a filter context | query_and |
query_sort_field |
Sort by _meta.created descending |
query_and |
query_and |
Combine filter and sort into one query | function_search (query pin) |
number_default (10) |
Limit results to 10 | function_search (limit pin) |
The function_search block returns an array of matching documents. For queries that should return at most one result, use function_search_single_result instead.
Query Types Overview
| Query Block | What It Does |
|---|---|
query_bool_must |
All provided queries must match (AND logic). |
query_bool_should |
One or more queries should match (OR logic). |
query_bool_filter |
Filters results using a boolean query (does not affect scoring). |
query_bool_must_not |
All provided queries must not match (exclusion). |
query_bool_term_fields |
Exact match on a selected field. |
query_bool_range_field |
Range comparison (greater than, less than) on a numeric field. |
query_bool_range_date_field |
Range comparison on a date field. |
query_bool_exists_bpfield |
Check if a field exists in the document. |
query_bool_wildcard_string_field |
Wildcard matching on a field value. |
query_bool_prefix_string_field |
Check if a field value starts with a given prefix. |
query_bool_term_fuzzy |
Find documents with terms similar to the search term (fuzzy matching). |
Search Tips
"Joe" and search for "joe", the document will not be found. It is good practice to store searchable values in lowercase to ensure accurate search results. - Use
get documentwhen possible: Retrieving by_meta.guidis the fastest method and easy to cache. Avoid custom unique identifiers. - Use
query_bool_filterfor most queries: Filter context is more efficient thanmustbecause it skips relevance scoring. - Limit your results: Always set a reasonable limit. Smaller result sets are faster to return and process.
- Select specific fields: Use
query_source_by_fieldto return only the fields you need. - Stream large result sets: Use
function_search_streamto process results as they arrive rather than loading everything into memory.
Real-Time Search Results
By default, search queries do not wait for the most recent inserts to be indexed. If you create a document and immediately search for it, it might not appear yet. In most cases this slight delay is acceptable.
If you need the absolute latest data, use the disable cache query block. This forces the system to wait until all pending inserts are indexed before running the search. In high-insert environments, this can introduce noticeable delays.
Full-Text Search
The storage includes a built-in full-text search engine. The main blocks for text searching are:
query_bool_simple_query_string_field: for user-facing search inputs. Handles common search syntax.query_bool_wildcard_string_field: for pattern matching with wildcards.query_bool_prefix_string_field: for autocomplete-style "starts with" searches.query_bool_term_fuzzy: for fuzzy matching that tolerates typos.
Remember that searches are case-sensitive. Store searchable text in lowercase and convert user input to lowercase before searching.
Data Modelling Without Relations
RUAL storage does not support relationships between storage entities. There are no SQL-style joins. Instead, denormalize your data: include all the information you need within each document.
Example: Orders and Customers
In a relational database, you'd have a separate customers table and reference the customer ID from orders. In RUAL, include the relevant customer information directly in the order document:
{
"order_number": "ORD-2024-0042",
"status": "shipped",
"total": 15990,
"customer_name": "joe doe",
"customer_email": "joe@example.com",
"customer_guid": "a23575f49d0af385314c1f02280163374297e018a692e5e4ab85eb307ebf6ebc",
"items": [
{ "name": "widget", "quantity": 3, "price": 5330 }
],
"_meta": {
"guid": "d56808172a3d26b86472153355496fa752ae341bc915e80b19de63a920e89203",
"expiry": -1,
"entity": 1,
"removed": 0,
"created": 1706396400,
"updated": 1708393100,
"ums": 1708393100132,
"cms": 1706396400362,
"update_hash": "3d82f70b5ce1946a208bd4f6019e7c5a86bb42d1"
}
}This way, searching for orders gives you the customer name and email without a second query. If a customer changes their name, update all their order documents using a storage event on the customers storage.
Denormalization Strategies
- Embed frequently accessed data: Store
customer_nameon every order instead of justcustomer_guid. - Keep a reference GUID: Always store the
guidof related documents so you canget documentwhen you need the full data. - Use storage events for sync: When a source document changes (e.g., customer name), use a storage event to update all documents that embed that data.
- Store counters separately: Instead of aggregation queries, maintain a counter field on a parent document and increment it when child documents are created.
Document Lifecycle
| Operation | Block | Notes |
|---|---|---|
| Create | function_create_document |
Returns the created document with _meta. Triggers on_created and on_saved storage events. |
| Read | function_get_document |
Fastest retrieval method by guid. Preferred over search for single documents. |
| Search | function_search |
Full-text search with query blocks. Results may have a slight indexing delay. |
| Update | function_update_document |
Transaction-based. Creates a revision if enabled. Triggers on_updated and on_saved events. |
| Remove (soft) | function_remove_document |
Marks as removed but data stays. Excluded from search by default. Can be restored. |
| Restore | function_restore_document |
Restores a removed document back to active state. |
| Delete (permanent) | function_delete_document |
Permanently deletes. Cannot be recovered unless revisions are enabled. |
remove (soft delete) in most cases instead of permanent delete. This allows recovery if needed. You can set up a repeating event to permanently purge removed documents after a retention period. Document Removal
Documents can be removed and restored at any time. Use function_remove_document or function_remove_multiple_documents to soft-remove documents. This is different from permanent deletion with function_delete_document.
Removed documents are tagged as such, and a revision is created if revisions are enabled. Search queries exclude removed documents by default, but you can include them with the query_include_removed block.
Restoring is straightforward with the function_restore_document block. The data is never actually deleted from storage. A good practice is to remove documents first, then permanently purge them after a retention period.
Document Expiry
By default, documents don't expire (_meta.expiry is -1). You can set an expiry timestamp when creating or updating a document using the function_create_document and function_update_document blocks.
To reset a document's expiry back to "never", use the date_never block, which sets _meta.expiry to -1. There is a slight delay before an expired document is physically deleted, but the get document block treats it as deleted once the expiry time has passed.
Caching with Redis
For high-traffic applications, cache search results in Redis instead of querying storage on every request. Common patterns:
- Cache frequently accessed search results with a TTL using
redis cacheblocks. - Invalidate or update the cache when documents change, using storage events.
- Store aggregated statistics in Redis and update them periodically with repeating events.
Frequently asked
What is _meta in a RUAL storage document?
_meta is the object every document carries with its guid, expiry, entity, removed state, created and updated timestamps, the ums and cms millisecond timestamps, and the update_hash of the last modification. It is never empty.
How do concurrent updates work in RUAL storage?
Updates go through mutations and are processed sequentially per document, so concurrent updates do not overwrite each other. That makes counters and array operations safe to use.
Can I use dots in a RUAL storage field name?
No. Field names are stored in lowercase and cannot contain dots. If a field name contains a dot, RUAL converts it into a nested object structure instead.